 R 함수 [문자 함수, 숫자 함수, 날짜 함수, 변환 함수, 일반 함수]
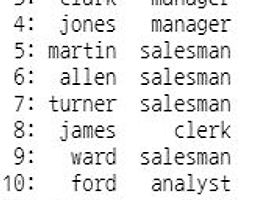
# 함수 종류 1. 문자 함수2. 숫자 함수3. 날짜 함수4. 변환 함수5. 일반 함수 # 문자 함수 오라클 vs R upper toupperlower tolowersubstr substrreplace gsub 예제 : 이름과 직업을 출력하는데 소문자로 출력 library(data.table)data.table(이름=tolower(emp$ename), 직업=tolower(emp$job) ) 예제 : 이름을 출력하고 그 옆에 이름의 첫번째 철자부터 세번째 철자까지 출력 문법 : substr( 변수, 시작, 끝 ) SQL> select ename, substr(ename, 1, 3) from emp; R> data.table( 이름=emp$ename, 철자=substr(emp$ename,1,3) ) 예제 :..
R 함수 [문자 함수, 숫자 함수, 날짜 함수, 변환 함수, 일반 함수]
# 함수 종류 1. 문자 함수2. 숫자 함수3. 날짜 함수4. 변환 함수5. 일반 함수 # 문자 함수 오라클 vs R upper toupperlower tolowersubstr substrreplace gsub 예제 : 이름과 직업을 출력하는데 소문자로 출력 library(data.table)data.table(이름=tolower(emp$ename), 직업=tolower(emp$job) ) 예제 : 이름을 출력하고 그 옆에 이름의 첫번째 철자부터 세번째 철자까지 출력 문법 : substr( 변수, 시작, 끝 ) SQL> select ename, substr(ename, 1, 3) from emp; R> data.table( 이름=emp$ename, 철자=substr(emp$ename,1,3) ) 예제 :..







