320x100
import requests
import pandas as pd
from pandas.io.json import json_normalize
import json
import time
import numpy as np
#import matplotlib.pyplot as plt
#import seaborn as sns
#plt.rcParams['font.family'] = 'Malgun Gothic'
api_key='RGAPI-d4ad985b-91c1-43d5-93c1-dd134d46c4ae' #매일 API 갱신해야함
REGION_SET = 'kr'
my_summoner_name='외 7' #내 롤 닉네임번거롭지만 API는 매일 Riot Developer Portal에 들어가서 갱신해줘야한다.
API만 갱신해서 바꿔주고, 모듈을 불러온다.
request_header={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36",
"Accept-Language": "ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7",
"Accept-Charset": "application/x-www-form-urlencoded; charset=UTF-8",
"Origin": "https://developer.riotgames.com"
}
summoner_api = 'https://kr.api.riotgames.com/lol/summoner/v4/summoners/by-name/'+my_summoner_name+\
'?api_key=RGAPI-7680e063-2c02-45b2-aa24-9c3eef0fcf14&api_key='+ api_key
r = requests.get(summoner_api,headers=request_header) #내 롤 닉네임 정보 호출
pd.DataFrame(r.json(),index=[0]).T
내 아이디 Puuid 를 뽑아내기 위한 과정
puuid=r.json()['puuid']
request_header={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36",
"Accept-Language": "ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7",
"Accept-Charset": "application/x-www-form-urlencoded; charset=UTF-8",
"Origin": "https://developer.riotgames.com",
"X-Riot-Token": api_key
}
summoner_api = 'https://asia.api.riotgames.com/lol/match/v5/matches/by-puuid/'\
+ puuid + '/ids?'\
+'type=ranked&start=0&count=20&' + api_key # 랭크게임만, 최근 20경기
r = requests.get(summoner_api,headers=request_header)
game_list=r.json()
game_list
최근 랭크 20게임 정보를 불러온다.
여기까지는 지금까지 했던 것
이제는 퀸 분석을 위해
게임 내 퀸이 있는 게임만 저장해보자.
Quinn_list=[]
for i in game_list:
request_header={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36",
"Accept-Language": "ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7",
"Accept-Charset": "application/x-www-form-urlencoded; charset=UTF-8",
"Origin": "https://developer.riotgames.com",
"X-Riot-Token": api_key
}
summoner_api = 'https://asia.api.riotgames.com/lol/match/v5/matches/' + i #+ '/timeline'
r = requests.get(summoner_api,headers=request_header)
df=pd.DataFrame(r.json())
pt_df=pd.DataFrame(df['info']['participants'])
if len(pt_df[(pt_df['championName']=='Quinn')&(pt_df['teamPosition']=='TOP')])==1: #특정 유저가 탑이면서, 퀸인 경우
Quinn_list.append(i)
Quinn_list
근데 과정중에 발견한 것이, ID별로 'lane' 이라는 컬럼도 있었는데 이게 top, mid 이런 식으로 라인명이 나와서
이게 해당 게임 내 라인을 말하는 줄 알고 사용하고 있었는데,
하다보니 같은 팀 내에 'top'이 둘인 경우도 있어서 이게 뭐지? 했었더니 해당 ID의 주 포지션이었다.
그리고 내가 생각한 게임 내 라인은 lane이 아니라 teamPosition이라는 컬럼이었다.
즉, 미드 라이너가 탑에 걸려서 탑에 가면
lane : mid
teamPosition : top
으로 나타나니 처음 쓰는 사람은 나처럼 혼동하지 않게 조심하자.
그건 그렇고 ID 별로 주 포지션을 이미 DB에 갖고 있다니 놀라웠다.
라이엇아, 그래서 계속 딴 라인 잡아줬던거니;;
어쩐지 탑 서폿만 주로 하다가 가끔 탑미드로 돌려도 결국 서폿 걸리더라
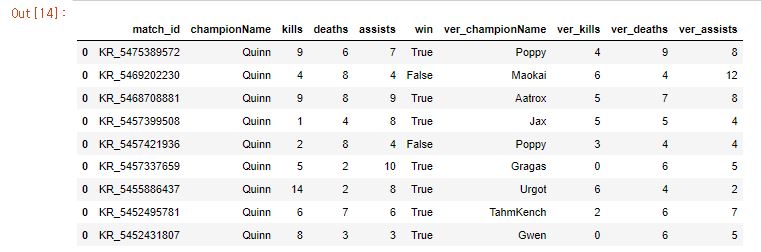
final_df=pd.DataFrame(columns=['match_id','championName','kills','deaths','assists','win','ver_championName','ver_kills','ver_deaths','ver_assists'])
for i in Quinn_list:
request_header={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36",
"Accept-Language": "ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7",
"Accept-Charset": "application/x-www-form-urlencoded; charset=UTF-8",
"Origin": "https://developer.riotgames.com",
"X-Riot-Token": api_key
}
summoner_api = 'https://asia.api.riotgames.com/lol/match/v5/matches/' + i #+ '/timeline'
r = requests.get(summoner_api,headers=request_header)
df=pd.DataFrame(r.json())
pt_df=pd.DataFrame(df['info']['participants'])
Quinn_df=pt_df[(pt_df['teamPosition']=='TOP')&(pt_df['championName']=='Quinn')][['championName','kills','deaths','assists','win']] # 탑,퀸의 KDA, 승리여부
Quinn_ver_df=pt_df[(pt_df['teamPosition']=='TOP')&~(pt_df['championName']=='Quinn')][['championName','kills','deaths','assists','win']] # 탑, 퀸이 아닌 챔피언의 KDA, 승리여부
Quinn_df['match_id']=i # 공통컬럼을 위해 match_id 부여
Quinn_ver_df['match_id']=i # 공통컬럼을 위해 match_id 부여
Quinn_ver_df.columns = 'ver_' + Quinn_df.columns #컬럼을 옆으로 붙이기 위해 컬럼명 변경
final_df=pd.concat([final_df,pd.merge(Quinn_df,Quinn_ver_df,left_on='match_id',right_on='ver_match_id').drop(columns=['ver_win','ver_match_id'],axis=1)]) # match_id로 join 뒤 불필요컬럼 제거
final_df
final_df.to_csv("Quinn_KDA_data.csv", mode='w')pd.read_csv("Quinn_KDA_data.csv", index_col=0)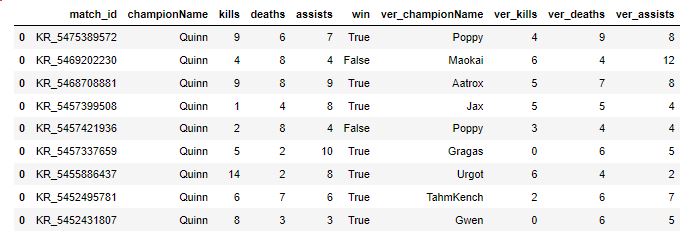
이제는 이런 식으로 데이터를 정제시켜서 저장할 수 있다는 것까지 확인했다.
그럼 지금부터는
1. 데이터를 쌓을 때 지금 KDA와 승리 여부만을 선택할 것인지, 다른 정보를 추가시킬 것인지 고민하는 것
2. 데이터를 쌓는 것
두 가지 과정이 필요할 것 같다.
반응형
'리그오브레전드 > 리그오브레전드 데이터 분석' 카테고리의 다른 글
| [리그오브레전드 데이터 분석] 리그오브레전드 API 탐색 - 3 (0) | 2021.10.05 |
|---|---|
| [리그오브레전드 데이터 분석] 리그오브레전드 API 탐색 - 2 (0) | 2021.10.04 |
| [리그오브레전드 데이터 분석] 리그오브레전드 API 탐색 - 1 (0) | 2021.09.30 |
| [리그오브레전드] (챔피언 퀸) 데이터 분석 프로젝트 (0) | 2021.09.29 |



